DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
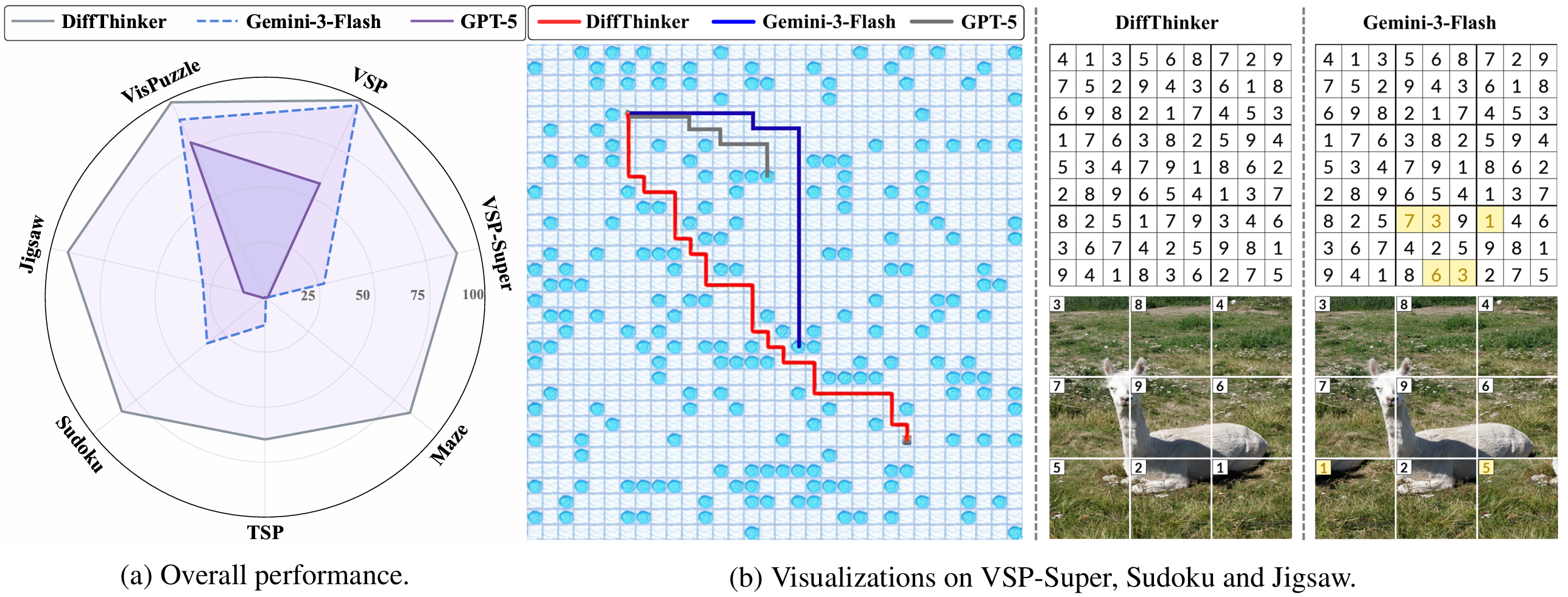
While recent Multimodal Large Language Models (MLLMs) have attained significant strides in multimodal reasoning, their reasoning processes remain predominantly text-centric, leading to suboptimal performance in complex long-horizon, vision-centric tasks. In this paper, we establish a novel Generative Multimodal Reasoning paradigm and introduce DiffThinker, a diffusion-based reasoning framework. Conceptually, DiffThinker reformulates multimodal reasoning as a native generative image-to-image task, achieving superior logical consistency and spatial precision in vision-centric tasks. We perform a systematic comparison between DiffThinker and MLLMs, providing the first in-depth investigation into the intrinsic characteristics of this paradigm, revealing four core properties: efficiency, controllability, native parallelism, and collaboration. Extensive experiments across four domains (sequential planning, combinatorial optimization, constraint satisfaction, and spatial configuration) demonstrate that DiffThinker significantly outperforms leading closed source models including GPT-5 (+314.2%) and Gemini-3-Flash (+111.6%), as well as the fine-tuned Qwen3-VL-32B baseline (+39.0%), highlighting generative multimodal reasoning as a promising approach for vision-centric reasoning.